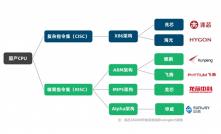
优化计算引擎
针对特定任务打造内核是一项成功的策略。“可编程DSP是分担CPU密集计算应用的理想选择,”Cadence的Tensilica IP产品管理、营销和业务开发高级主管Lazaar Louis说。“DSP灵活、可编程,而且支持Open VX和Open CL等开放式、跨平台的加速标准,可轻松将应用程序移植到DSP。对于某些常见应用,DSP还可以与专用硬件加速器配合使用,不仅可以发挥加速器的更高功效,还可以结合DSP的可编程能力,从而满足应用在产品生命周期中不断变化的需求。”
许多架构都因为没有提供强大的软件开发环境而失败了。“GPU是一个通过打造成本可持续的独立开发环境和软件生态系统而大获成功的典型例子。”Whitfield说。“有的机器学习算法看起来需要一些专业的加速器,它们将作为一种粗粒度的加速引擎和通用CPU一起使用。”
GPU的成功之路非常有意思。“GPU是一种针对特定域的架构,刚开始主要面向游戏,现在又被用到区块链和神经网络上,”Ruparelia指出。“GPU有一些传统CPU上很难实现的功能,针对特定域优化的体系结构能够实现更高的单元计算性能和软件生产力。神经网络是一个典型的例子,和一个专门针对它设计的可编程平台相比,如果你在CPU上运行它,将花费10倍之多的运行时间和功耗。”
但是GPU并没有针对神经网络进行专门优化。“在卷积神经网络中,80%的时间都消耗在卷积运算上,”GreenWaves的Croome说。 “卷积有各种形式,运算量也各有大小。涉及到的概念有填充、膨胀、步幅以及滤波器的大小等。卷积有许多参数,如果你试图构建一个可以在硬件中完成所有卷积运算的系统,这个系统将使用大量当前已知的硬件。你必须使用最常见的卷积参数,并构建一些能够保持足够灵活性的东西。”
那么,是不是有人可以为定制加速器提供完整的软件开发环境呢?
“我们正在编写优化的内核,并给一些矢量化的运算进行了手工编码,”Croome继续说道。“我们使用了标准的向量操作,但是即便如此,你写代码时,当涉及到寄存器加载操作时,也需要考虑如何优化编码,以便编译器能够以一种特定的方式定位到它。”
这就是加速器的编码开始变得困难的地方。Synopsys解决方案事业部产品营销经理Gordon Cooper说:“使用一组GPU或CPU训练神经网络,然后在GPU上运行该神经网络非常容易。人们可以通过Caffe或TensorFlow做到这一点。但是,当我们使用专用硬件满足嵌入式系统的要求,比如低功耗、小尺寸时,GPU只能保证性能,却无法保证能效。使用异构方案的缺点是,无论是加速器还是专用处理器,都有各自不同的工具链或者多个工具链,你需要学习并管理好它们,这可不像给GPU编程那么简单。”
这是一种微妙的平衡。“使用GPU的优势是很灵活,但是无法保证功耗和尺寸,另一方面,没有编程环境,或者很难使用,一样会让你举步维艰,”Cooper补充道。“在加速器上变成永远不会像为CPU编写代码那样简单。你可以参照DSP世界的编程进行优化,先用C语言编程,然后优化内部的循环体。这是一种平衡。”
改换硬件
长期以来,FPGA都自我标榜为可编程的硬件。“硬件RTL工程师可以将FPGA用作可编程平台,这没有任何问题,”Rupatelia说。“但是,当软件工程师把FPGA作为一种可编程平台时,麻烦就来了。这个挑战已经存在很长时间了。”
今天,FPGA也被嵌入到了ASIC中。“eFPGA IP是异构方案的一种元素,怎么个用法取决于架构定义和代码的划分,”Menta的Dupret说。 “HLS工具可以为此提供帮助,但最终的目标是为异构体系结构自动化地进行代码划分。我们现在还没有实现这个目标,但我们确信这是行业发展的方向。”
这也很可能成为物联网硬件开发的重要一环。“我们如何确保物联网设备的灵活性,并且可以现场升级?”Allan问道。“可以需要结合使用软件和智能FPGA技术,它们都是当今CPU解决方案里的技术。我们现在谈论的是,定义产品时更少依赖硬件/软件交互,更多依赖编译好的逻辑器件、内存和可编程器件,以实现产品的灵活性。”
这可能意味着改变对软件的传统看法。Ruparelia指出:“当今的FPGA工具链依然不支持软件工程师在不了解FPGA的情况下直接使用它,这方面的进展甚微。不过,现在可以更加容易地针对特定领域或特定应用进行编程了。我们正在研究神经网络上使用的非常具体的中间件,它们抽象出了FPGA的复杂性,并保留了足够的灵活性,可供上层软件调用。”
除了处理单元,内存架构也存在进一步改进的压力。“硬件加速器正在部署更多可用内存,”Shuler说。“芯片到DRAM或HBM2的通信越少,效率就越高。我们该怎样把所有数据都保存在处理单元中,并在处理单元之间交互?处理器单元有时会有自己的暂存存储器,有时会连接到网格里的存储器中,那样的话,存储器就被分割开来,在整个架构中散落地无处不在。”
“我们结合芯片和处理器开发了多级缓存架构,将内容可寻址内存作为控制优化的关键技术,”Allan解释道。“然后我们开始研究一致缓存架构,其中,多个处理器围绕在共享内存空间周围,互相协作。现在,我们在计算器件中引入了神经网络,内存也是一个关键因素。内存技术将继续演进,我们会发现新的方案不断出现。HLS将发展为允许定制内存架构,以帮助加速特定算法。在这个领域有许多创新,可以将算法输入到HLS流中,并使用智能内存技术优化解决方案。”
和通用CPU形态相差最远的是专用硬件解决方案。“这是一种单线程编程模型,存在实打实的限制,”Klein指出。“将一个算法从CPU上转移到没有引入任何并行性的定制硬件上固然也可以提高效率,但是达不到人们的预期。进一步提升效率的关键在于找出并利用算法里的并行性。”
最终,需要软件思想的革新,推动设计人员以并行的方式实现各种算法。