关于大小端存储的问题,在嵌入式开发里这个早已不是什么新鲜事儿了。作为开发者都有着很清晰的认识,在此就嵌入式开发中的大小端问题,做个简单的分享总结。
大端小端,是相对内存而言的。有关大小端的资料,互联网上一搜就一大堆的博文和百科知识点,这里就不再赘述。
在工程项目中,需要处理大小端差异的,主要出现在数据处理的过程中,常见的有:
1.数据包解析和组包
2.数据收发和参数传递
数据包解析和组包
数据包解析和组包的过程,可以参考《嵌入式硬件通信接口协议-UART(四)设计起止式的应用层协议》该文中的“设计协议帧结构”部分,该部分内容讲到把uint16_t字段的数据使用2个uint8_t类型的数据表示,旨在数据传输时没有差异。
但是,有些接口是别人设计好的,作为应用者你只能“顺从”地使用。
在C语言里可以利用强制转换来实现对数据类型的转换,但是强转的结果依赖于当前平台大、小端情况的。
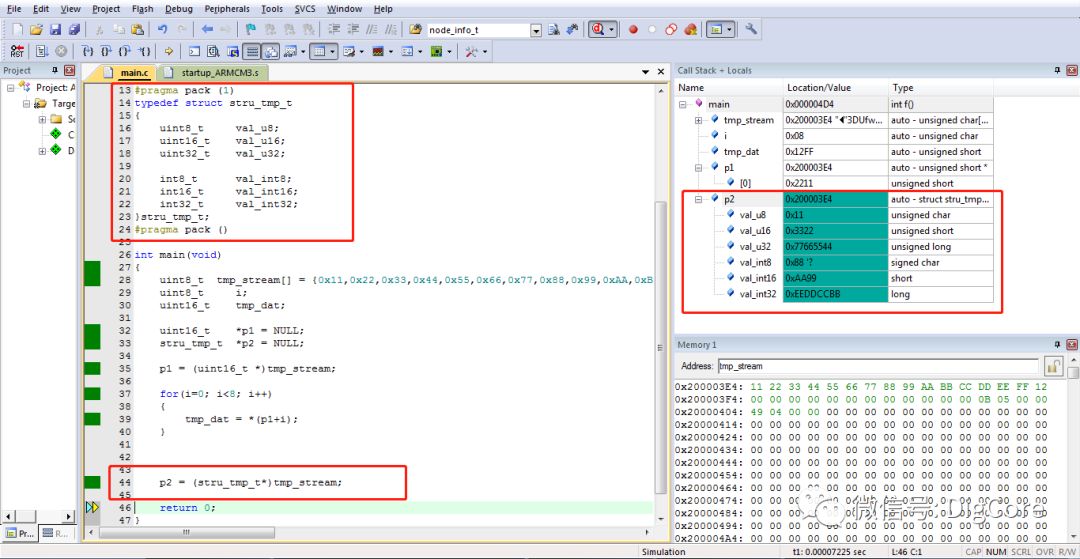
如下的类型强制转换,将uint8_t类型buf中的数据流强制转为uint16_t类型后取出赋值给tmp_dat变量,根据观察发现buf中的数据流被每2个字节“组合”成一个uint16_t类型的数据,Debug过程截图如下:

代码中的p1是一个uint16_t类型指针,指向uint8_t类型数据流的tmp_stream,此处的指针赋值就需要使用强制转换。
在for循环内以p1指针为“起点”循环做偏移取出数据,并且每次偏移uint16_t类型的数据宽度,因为p1是uint16_t类型指针。
观察取出数据存放的tmp_dat变量,可见数据被从左到右(也就是从低地址到高地址)每2个字节“组合”成uint16_t类型,比如0x11和0x12组合成0x1122,0x33和0x44组合成0x3344......可见,低地址的那一个数据组合后成为了uint16_t的高字节部分!这就是大端模式!
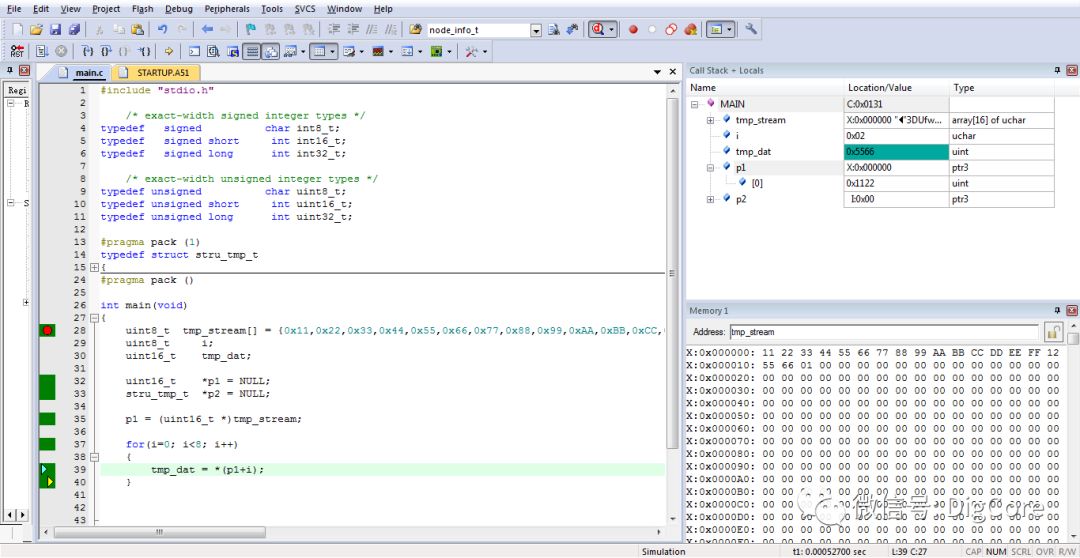
同样的代码,拿到小端模式的ARM平台里运行,结果就完全不一样了:

不难发现,在小端平台里,数据被从左到右(也就是从低地址到高地址)每2个字节“组合”成uint16_t类型了,而此时0x11和0x12组合成0x2211,同时0x33和0x44组合成0x4433……可见,低地址的那一个数据组合后成为了uint16_t的低字节部分!这就是小端模式!
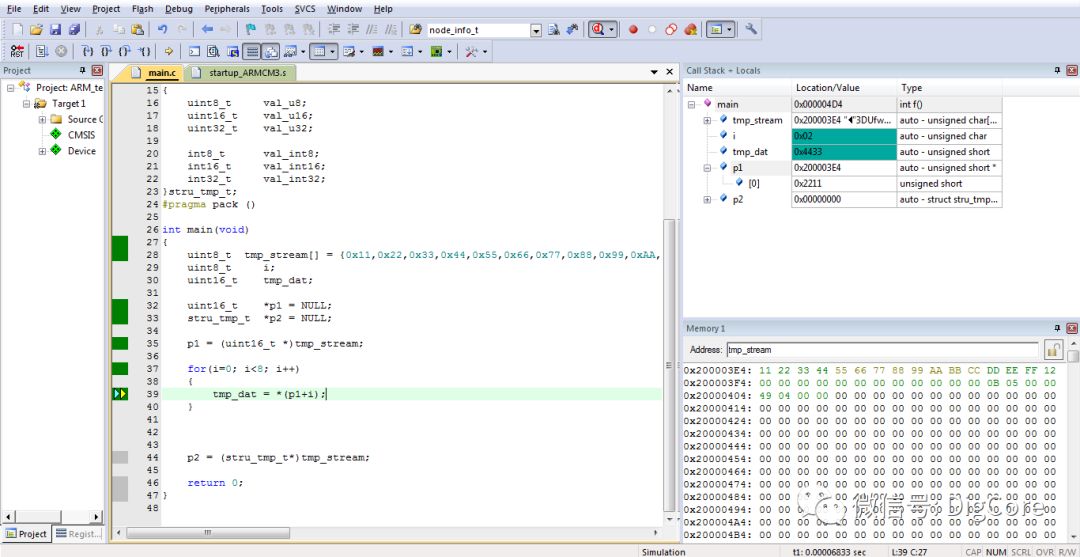
类似的问题,也会出现在强制转换为结构体的过程中,并且实际得到的结构体由于大小端问题,部分成员已经“变了样”!
使用同一数据流,利用一结构体指针p2指向该数据流进行解析,对比不同平台强制转换后的结构体部分成员的情况。
大端模式的51平台下:

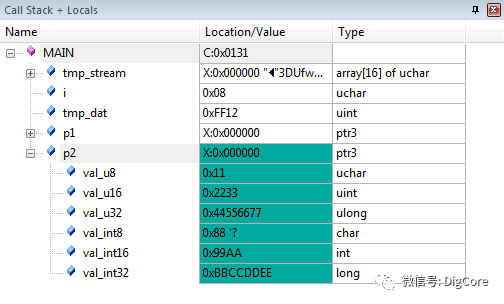
小端模式的ARM平台下: