芝能智芯出品
接昨天的文章(AWS不用英伟达GPU,打造与众不同的超级计算机),AWS推出的自研AI芯片Trainium及其升级版Trainium 2,正在重塑云计算和AI训练领域的格局,我们开始来看这颗芯片的细节。
Trainium 2以显著增强的性能和架构设计,填补了上一代芯片的不足,通过650 TFLOP/s的计算能力和96GB的HBM3内存支持,面向大规模生成式AI模型训练与推理。
随着Rainier项目中40万颗Trainium 2芯片的部署,AWS正在全球范围内推动ExaFLOPS级超级计算集群的应用。
我们来分析Trainium系列芯片的技术演进及其对AI计算未来的影响,并展望其迭代方向和AWS的战略潜力。
Part 1
从Trainium到Trainium 2:技术升级与核心改进
● 什么是Trainium处理器?

Trainium是AWS于2022年推出的首款AI加速器,旨在支持深度学习模型的训练和推理。
作为Inferentia的升级版,Trainium 1提供了一定的并行计算能力,但由于互连网络性能有限(NeuronLink-v2)、软件集成度不足,其在生成式AI(GenAI)训练中的竞争力不强。

Trainium 1在 GenAI 前沿模型训练或推理方面暴露出明显的短板,Trainium1 具备四个端口,而 Inferentia2 仅有两个,关键的问题在于其纵向和横向扩展网络缺乏竞争力,这一缺陷严重制约了它们在大规模 GenAI 训练任务中的表现。
众多软件错误的存在,也进一步干扰了客户工作负载的正常运行,使得这两款芯片难以在 GenAI 核心领域施展拳脚。

● Trainium 2的架构与设计改进
Trainium2 应运而生,成为 AWS 在 AI 芯片领域战略调整的关键棋子,设计目标明确指向复杂的 GenAI LLM 推理和训练工作负载,旨在弥补前代产品的不足,并在与其他竞品的竞争中占据一席之地。
变革的驱动力主要源于市场对高效、强大的 AI 芯片的迫切需求,以及 AWS 自身在 AI 领域扩张战略的推动。

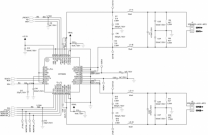
Trainium 2采用了更高效的设计,每颗芯片包含两个计算芯片组和四个HBM3堆栈,支持96GB内存和高达46TB/s的带宽。
通过NeuralLink-v3网络,Trainium 2实现了芯片间更快速的通信,能够形成64芯片的3D环面拓扑。
● 性能提升:
◎ 计算能力:650 TFLOP/s的BF16性能(相比Trainium 1显著提升)。
◎ 扩展能力:支持Trn2-Ultra配置,可连接64颗芯片,形成大规模并行计算能力。
◎ 能效比:优化的互连网络设计显著降低了通信功耗,提升整体能效比。

Trainium2 是一款专为大规模AI模型训练和推理设计的高性能芯片,运行功耗约为500W,提供650 TFLOP/s的BF16性能,并配备96GByte HBM3e内存。
其NeuronLinkv3扩展网络通过铜背板实现高效的服务器内芯片间连接,每个芯片利用JBOG PCB上的PCB走线及32个PCIe Gen 5.0通道(每条通道32Gbit/s单向),与其他三个服务器内芯片通信,形成2x2x2x2超立方体网格结构,等同于4×4 2D环面。

这种拓扑确保了低延迟、高带宽的数据交互,特别适用于多芯片协同处理任务,如大规模矩阵运算。
在服务器间,NeuronLinkv3通过有源电缆连接四台物理服务器,构建一个64芯片的4x4x4 3D环面结构,Z轴带宽64GByte/s,X和Y轴带宽128GByte/s,支持高效张量并行和激活分片,提升集群计算能力。
Trainium2采用少量大型NeuronCore设计理念,对比传统GPU的小型张量核心,更适应GenAI工作负载。

● 每个NeuronCore包含:
◎ 张量引擎:128×128脉动阵列,承担主要计算任务。
◎ 矢量引擎:加速矢量运算,如softmax计算。
◎ 标量引擎:执行简单映射操作,如偏差添加。
◎ GPSIMD引擎:允许自定义C++代码执行,增强功能扩展性。
Trainium2拥有专用集体通信核心,优化芯片间通信效率,避免资源争用,减少通信延迟对整体训练效率的影响。然而,预先确定的资源比例可能限制其对不同工作负载的适应性,某些情况下可能导致资源闲置或成为性能瓶颈。
每个 Trainium2 芯片由两个计算芯片组和四个 HBM3e 内存堆栈组成。计算芯片组通过 CoWoS - S / R 封装与相邻的 HBM3e 堆栈通信,芯片的两半则通过 ABF 基板相互连接,封装结构在保证芯片内部数据传输效率的同时,也面临着一些挑战,如当计算芯片组访问非直接相邻的 HBM 堆栈内存时,性能会略有下降!
Trainium 2在硬件性能和扩展性上取得了重大突破,但其扩展网络的算术强度(225.9 BF16 FLOP/字节)仍低于Google TPUv6e和Nvidia H100的300-560 BF16 FLOP/字节,NeuronLink的拓扑规模(64芯片)也小于TPU的256芯片世界规模。
AWS通过优化软件堆栈和高效的扩展网络设计,弥补了部分差距,使Trainium 2成为一款兼具性能和成本优势的AI芯片。


Trainium2 和 Trainium2-Ultra 服务器采用独特设计,每个物理服务器占用18个机架单元(RU),由一个2U CPU托盘和八个2U计算托盘组成。这种架构通过无源铜背板以点对点方式连接计算托盘,形成4×4 2D环面结构,减少了传统交换机带来的延迟和带宽损耗。
每个计算托盘包含两个Trainium芯片,被称为“一堆GPU”(JBOG),依赖CPU托盘进行控制和数据交互。普通Trn2实例的计算托盘配备8个200G EFAv3 NIC,提供高达800Gbit/s的横向扩展带宽。

Trn2-Ultra SKU则专注于构建64芯片的纵向扩展网络,横向扩展带宽为200Gbit/s,通过有源电铜缆连接四台物理服务器,实现大规模集群扩展。CPU托盘内的PCIe交换机连接计算托盘与本地NVMe磁盘,使Trainium2能通过GPUDirect-Storage直接访问存储,提高数据读取速度。

托盘还配备了80Gbit/s弹性块存储链路和100Gbit/s Nitro卡(ENA),用于与外部存储设备和网络连接。CPU托盘内含两个Intel Xeon Sapphire Rapids CPU和最多2TB的DDR5内存,采用48V DC配电系统,确保稳定运行。
NeuronLinkv3互连技术在Trn2-Ultra中将64个芯片连接成4x4x4 3D环面结构,提升了单服务器内及跨服务器间的通信效率。这种设计使得Trainium2系列服务器成为处理复杂AI工作负载的理想选择。

Part 2
Trainium系列芯片的影响与未来趋势
Trainium2 在计算性能和内存容量之间取得了较好的平衡。其 650 TFLOP/s 的密集 BF16 性能与 96GByte 的 HBM3e 内存容量相匹配,能够在处理大规模数据时减少内存瓶颈对计算效率的影响。
例如,在 LLM 训练过程中,模型参数和中间数据的存储与读取能够与计算操作高效协同,避免因内存不足或带宽受限导致的计算停顿。

NeuronLinkv3 的扩展网络拓扑为 Trainium2 提供了强大的扩展能力。无论是服务器内的 2D 环面结构还是服务器间的 3D 环面结构,都能够根据不同的任务需求和集群规模进行灵活配置。
◎ 在小规模集群中,服务器内的高速连接可以满足快速的数据交互需求;
◎ 而在大规模集群中,服务器间的扩展网络能够实现跨服务器的高效协同计算,
◎ 如在构建超大规模的 LLM 推理集群时,能够将多个服务器的计算资源整合起来,提高整体推理速度。
张量引擎、矢量引擎、标量引擎和 GPSIMD 引擎的组合以及专用集体通信核心的设计,使得 Trainium2 能够针对不同类型的 AI 任务进行优化。
在 LLM 的矩阵运算、矢量运算、自定义操作以及芯片间通信等方面都能展现出较高的效率。例如,在处理自注意力机制中的复杂运算时,各个引擎能够协同工作,提高运算速度;而专用集体通信核心则在多芯片通信中减少延迟,提升整体性能。
● 高效扩展与灵活配置:Trainium 2通过NeuronLink网络支持2D/3D环面拓扑,可实现高效的张量并行和激活分片方案,适应从小规模到超大规模的计算需求。
● 成本与能效优化:自研芯片的成本效益使得AWS能够以更低的费用支持复杂的AI工作负载。
● 软硬件协同:通过与Neuron SDK和JAX等框架的深度整合,AWS大幅降低了开发者的使用门槛,提升了软硬件协同效率。
Trainium2 在硬件设计上取得显著进展,软件生态系统的完善仍是关键挑战。
目前,Pytorch XLA 与 Trainium2 的结合存在 API 不完善和代码路径维护的局限性。未来,AWS 需加强与 Meta 等公司的合作,优化 Pytorch 和 JAX 在 Trainium2 上的运行效率。
同时,持续开发和优化 Neuron Kernel Language (NKI),通过与高校及研究机构的合作,扩大开发者社区,提供培训资源、开源示例代码和举办开发者竞赛,吸引更多开发者使用 NKI 进行内核开发,丰富 Trainium2 的软件生态系统。
网络性能方面,NeuronLinkv3 和 EFAv3 已具备一定优势,但随着 AI 模型规模扩大和计算速度要求提高,仍有提升空间。可以探索更高带宽连接技术或优化网络拓扑结构以减少数据传输延迟。
● 对行业趋势的推动
◎ AI芯片自研成为主流,AWS的成功案例将鼓励其他云服务商(如Google、微软)加大AI芯片研发投入,从而推动整个行业向定制化加速器方向发展。
◎ 分布式AI超算的崛起,Rainier项目展示了AI集群在大规模部署中的潜力,未来类似的分布式超算架构将进一步普及,为全球AI研发提供基础设施支持。
◎ AI芯片性能和成本的优化,更多企业将能负担得起大规模生成式AI模型的训练与推理,推动其在各行业的广泛应用。
小结
AWS通过Trainium 2展示了自研AI加速器的潜力与价值,为生成式AI的快速发展提供了强大的硬件支持,芯片技术的不断迭代和集群规模的扩展,A自研芯片成为云服务商的核心竞争力。
芝能智芯,将持续为您带来AI芯片与技术趋势的专业分析,敬请期待。
原文标题 : AWS最强AI芯片 !Trainium 2技术细节解析