AI运算指以“深度学习” 为代表的神经网络算法,需要系统能够高效处理大量非结构化数据(文本、视频、图像、语音等) 。需要硬件具有高效的线性代数运算能力,计算任务具有:单位计算任务简单,逻辑控制难度要求低,但并行运算量大、参数多的特点。对于芯片的多核并行运算、片上存储、带宽、低延时的访存等提出了较高的需求。
AI应用场景的丰富带来众多碎片化的需求,基于此适配各种功能的处理器不断衍生。

CPU
CPU即中央处理器(Central Processing Unit),作为计算机系统的运算和控制核心,主要负责多任务管理、调度,具有很强的通用性,是计算机的核心领导部件,好比人的大脑。不过其计算能力并不强,更擅长逻辑控制。
正是因为CPU的并行运算能力不是很强,所以很少有人优先考虑在 CPU 上直接训练模型。不过芯片巨头英特尔就选择了这么一条路。
像英特尔? 至强? 可扩展处理器这种 AI build-in 的 CPU 在支持模型训练上已经有了极大地提升,去年由莱斯大学、蚂蚁集团和英特尔等机构的研究者发表的一篇论文中表明,在消费级 CPU 上运行的 AI 软件,其训练深度神经网络的速度是 GPU 的 15 倍,另外相比显存 CPU 的内存更易扩展,很多推荐算法、排序模型、图片 / 影像识别等应用,已经在大规模使用 CPU 作为基础计算设备。
相比价格高昂的 GPU,CPU 其实是一种性价比很高的训练硬件,也非常适合对结果准确度要求高兼顾成本考量的制造业、图像处理与分析等行业客户的深度学习模型。
GPU
GPU即图形处理器(Graphics Processing Unit),采用数量众多的计算单元和超长的流水线,擅长进行图像处理、并行计算。
对于复杂的单个计算任务来说,CPU 的执行效率更高,通用性更强;而对于图形图像这种矩阵式多像素点的简单计算,更适合用 GPU 来处理,也有人称之为人海战术。而AI 领域中用于图像识别的深度学习、用于决策和推理的机器学习以及超级计算都需要大规模的并行计算,因此更适合采用 GPU 架构。

多核 CPU 与 GPU 的计算网格(图中绿色方格为计算单元)
CPU和GPU还有一个很大的区别就是:CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要处理大量类型统一的数据时,则可调用GPU进行并行计算。但GPU无法单独工作,必须由CPU进行控制调用才能工作。
在AI计算领域英伟达的GPU几乎占到市场的绝大部分,但近几年也有不少国产企业进军高端GPU,比如沐曦首款采用7nm工艺的异构GPU产品已流片、壁仞前不久也发布了单芯片峰值算力达到PFLOPS级别的BR100,还有燧原科技、黑芝麻、地平线等公司都在向高端GPU发力。
DPU
DPU即数据处理器(Data Processing Unit),用于优化卷积神经网络,广泛应用于加速深度学习推理算法。
当CPU算力释放遇瓶颈,DPU能够卸载 CPU 的基础层应用(如网络协议处理、加密解密、数据压缩等),从而释放CPU低效应用端的算力,将CPU算力集中在上层应用。区别于GPU,DPU主要用于对数据解析与处理,提高数据接发的效率,而GPU则是专注于数据的加速计算。因此,DPU将有望成为释放CPU算力新的关键芯片,并与CPU、GPU形成优势互补,提高算力天花板。
DPU还具有高性能网络接口,能以线速或网络中的可用速度解析、处理数据,并高效地将数据传输到GPU和CPU。
英伟达收购Mellanox后,凭借原有的ConnectX系列高速网卡技术,推出其 BlueField系列DPU,成为DPU赛道的标杆。英伟达首席执行官黄仁勋也曾表示:“ DPU 将成为未来计算的三大支柱之一,未来的数据中心标配是‘ CPU + DPU + GPU ’。CPU 用于通用计算, GPU 用于加速计算, DPU 则进行数据处理。”
当下的DPU的市场,已经成为各个巨头和初创公司的必争之地,除英伟达等企业开始布局DPU产业外,阿里巴巴、华为在内的各大云服务商也逐渐跻身DPU行业。其他还有芯启源、大禹智芯、星云智联、中科驭数、云豹智能等公司。
TPU
TPU:张量处理器(Tensor Processing Unit)是谷歌专门为加速深层神经网络运算能力而研发的ASIC 芯片,专用机器学习的人工智能加速处理器。
AI 系统通常涉及训练和推断过程。简单来说,训练过程是指在已有数据中学习,获得某些能力的过程;而推理过程则是指对新的数据,使用这些能力完成特定任务(比如分类、识别等);推理是将深度学习训练成果投入使用的过程。
有老话言:万能工具的效率永远比不上专用工具。TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。此外,在 TPU 中采用 GPU 常用的 GDDR5 存储器能使性能TPOS指标再高 3 倍,并将能效比指标 TOPS/Watt 提高到 GPU 的 70 倍,CPU 的 200 倍。
2016年 TPU 消息刚刚公布时,谷歌资深硬件工程师Norman Jouppi 在谷歌Research 博客中特别提到,TPU 从测试到量产只用了 22 天,其性能把人工智能技术往前推进了差不多 7 年,相当于摩尔定律 3 代的时间。
IPU
IPU:图像处理单元(Intelligent Processing Unit),可以从图像传感器到显示设备的数据流提供全面支持,连接到相关设备,比如:摄像机、显示器、图形加速器、电视编码器和解码器。相关图像处理与操作包括传感器图像信号处理、显示处理、图像转换等,以及同步和控制功能。 采用的是大规模并行同构众核架构,同时将训练和推理合二为一,为AI计算提供了全新的技术架构,兼具处理二者工作的能力。
IPU是英国AI芯片创业公司Graphcore率先提出的概念,Graphcore的第一代IPU如今已在微软Azure云以及Dell-EMC服务器中使用,为AI算法带来了飞跃性的性能提升,也为开发者带来更广阔的创新空间及更多创新机会。
目前,IPU正在成为仅次于GPU和谷歌TPU的第三大部署平台,基于IPU的应用已经覆盖包括自然语言处理、图像/视频处理、时序分析、推荐/排名及概率模型等机器学习的各个应用场景。
2021年,英特尔推出了IPU技术,近日又和谷歌共同设计了新型定制基础设施处理单元(IPU)芯片 E2000 ,代号为“Mount Evans”,以降低数据中心主 CPU 负载,并更有效和安全地处理数据密集型云工作负载。
NPU
CPU和GPU的制造成本较高,功耗也比较大,加之AI场景下需要运算的数据量与日俱增,一种针对神经网络深度学习的高效智能处理器应运而生,也就是NPU。
NPU即神经网络处理器(Neural network Processing Unit),它是用电路模拟人类的神经元和突触结构。用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题,特别擅长处理视频、图像类的海量多媒体数据。
与CPU、GPU处理器运行需要的数千条指令相比,NPU只要一条或几条就能完成,且在同等功耗下NPU 的性能可以达到 GPU 的 118 倍,因此在深度学习的处理效率方面优势明显。NPU 目前较多地在端侧应用于 AI 推理计算,在云端也有大量运用于视频编解码运算、自然语言处理、数据分析,部分NPU还能运用于 AI 的训练。
比如在手机SoC中,CPU是负责计算和整体协调的,而GPU是负责和图像有关的部分,NPU负责和AI有关的部分,其工作流程则是,任何工作都要先通过CPU,CPU再根据这一块工作的性质来决定分配给谁。如果是图形方面的计算,就会分配给GPU,如果是AI方面的计算需求,就分配给NPU。
NPU具体的应用有:基于人脸识别的考勤机、基于 DHN(深度哈希网络)的掌纹识别、基于图像分类的自动垃圾分类、自动驾驶汽车、自动跟焦摄像机、监视系统等。
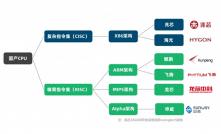
2014年中科院的陈天石科研团队发表了 DianNao 系列论文,随即席卷了体系结构界,开启了专用人工智能芯片设计的先河,后来中科院旗下的寒武纪科技推出了其第一代 NPU 寒武纪 1A,并用在了华为麒麟 970 芯片中,华为也推出了自研的基于 DaVince 架构的 NPU ,阿里则推出了“含光”架构的 NPU 。
随着芯片构造方式的变化,大量异构处理器方案也不断衍生,每个芯片都对处理器性能、优化目标、所需的数据吞吐量以及数据流做出了不同的选择。在这几大类处理器芯片中,IPU与DPU发展速度领先。随着5G边缘云、自动驾驶和车路协同、金融计算等带来越来越多的数据量,各种“X”PU的市场价值都在不断攀升。

原文标题 : 越来越卷的AI,“X”PU的各有所长